This time, I try to install bettercap docker image on raspberry Pi3B+.
Install dependency package first
1 | root@treehouses:~# apt install libnetfilter-queue1 |
Install bettercap docker image
1 | root@treehouses:~# docker pull bettercap/bettercap |
This time, I try to install bettercap docker image on raspberry Pi3B+.
1 | root@treehouses:~# apt install libnetfilter-queue1 |
1 | root@treehouses:~# docker pull bettercap/bettercap |
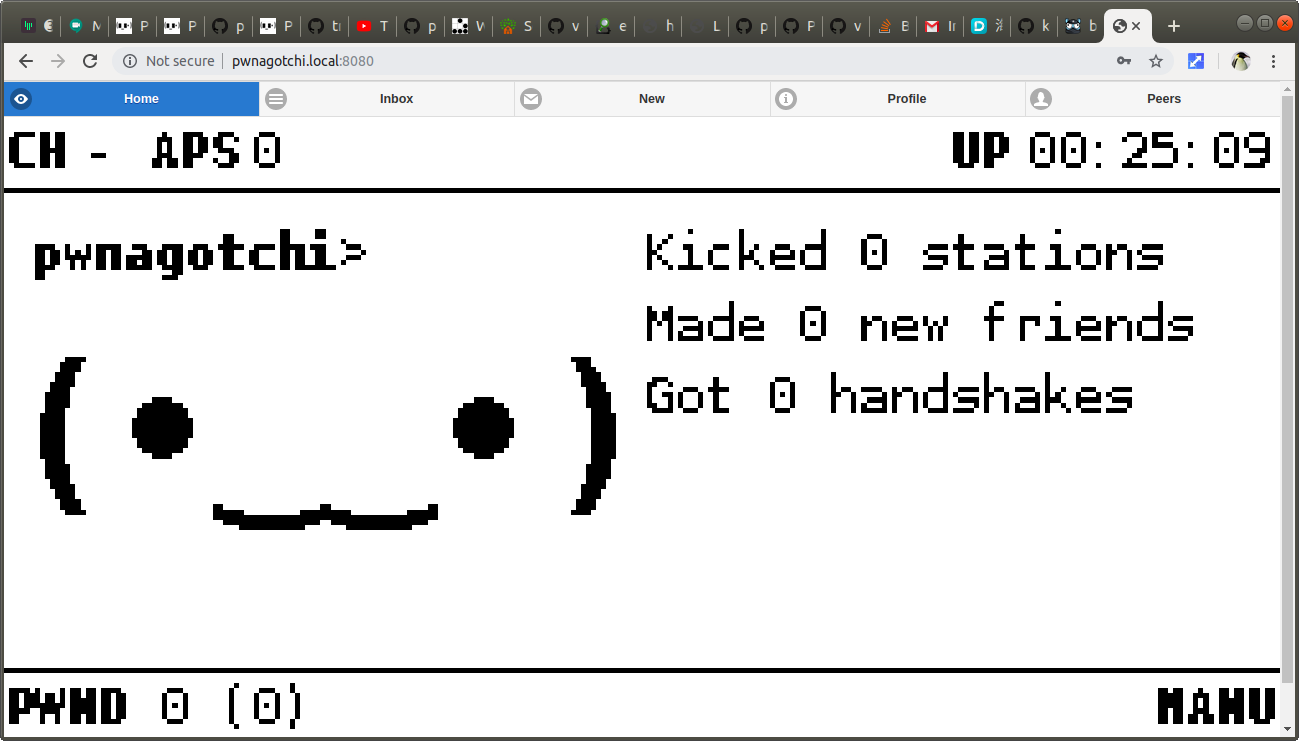
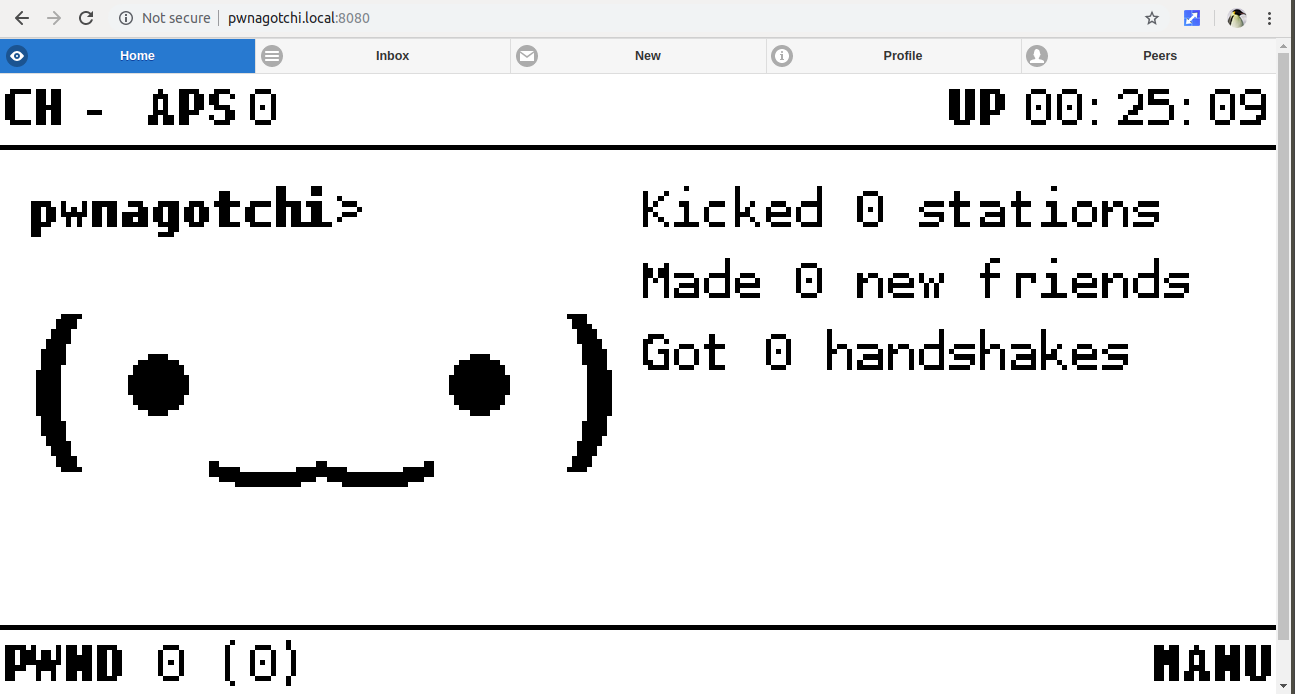
Pwnagotchi is an A2C-based “AI” powered by bettercap that learns from its surrounding WiFi environment in order to maximize the crackable WPA key material it captures (either through passive sniffing or by performing deauthentication and association attacks). This material is collected on disk as PCAP files containing any form of crackable handshake supported by hashcat, including full and half WPA handshakes as well as PMKIDs.
download the the latest image
then unzip it into present directory
1 | anna@ubuntu1804:~/Downloads$ dd if=pwnagotchi-raspbian-lite-v1.3.0.img of=/dev/sdcard |
before boot this image on RPI 3B+, I need to config it first. I mount this device to /mnt/1.
then add config.yml to it.
1 | main: |
Because I dont have RPi 0w, so I try to use web UI (instead of an e-ink display attached to RPi0W) to see your Pwnagotchi’s face.
I add these to my config.yml file
1 | ui: |
In order to reduce power requirements I can lower cpu frequency (underclocking). Edit my /boot/config.txt and uncomment the arm_freq=800.
It shows like following.
1 | Linux pwnagotchi 4.19.81-Re4son-v7+ #1 SMP Wed Nov 6 10:16:47 AEDT 2019 armv7l |
check the service
1 |
|
all the handshake eaten by pwnagotchi can be found under /root/handshake
1 | root@pwnagotchi:~/handshakes# ls -al |
This project uses npm config for configuration. I need to create config/local.json5 file to override the configuration as necessary, especially to define githubTokens. After working a lot, I found I need to clone the npm-analyzer repo actuallya. I do not know whether the work before is worthable if I already clone the whole repo.
under my npm_analyzer dirctory, clone the repo to my local machine.
1 | git clone https://github.com/npms-io/npms-analyzer.git |
1 | $ cp default.json local.json5 |
1 | vagrant@cli:~/npm_analyzer/npms-analyzer/config$ ls -al |
1 | { |
1 | { |
after checking default.json file, I found there are two databases, one is couchdbNpms which is for queue, and another one is couchdbNpm which is for replication from https://replicate.npmjs.com/registry. I only created npms, so I need to go back couchdb to create npm database and redo the replication work. It takes long time to replication the couchdb and also shows “error” for replication funtion on couchdb website.
elasticsearch is a scalable and speedy search, analytics, and storage.
1 | vagrant@cli:~/npm_analyzer$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
install the apt-transport-https package on Debian before proceeding.
1 | vagrant@cli:~/npm_analyzer$ sudo apt-get install apt-transport-https |
Save the repository definition to /etc/apt/sources.list.d/elastic-7.x.list
1 | vagrant@cli:~/npm_analyzer$ echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
check source list
1 | vagrant@cli:/etc/apt/sources.list.d$ ls -al |
1 | vagrant@cli:~/npm_analyzer$ sudo apt-get update && sudo apt-get install elasticsearch |
At first I go to RabbitMQ to download and install it.
I use the shell script to install rabbitMQ
1 | #!/bin/sh |
after run this instll shell script, it doesn’t work. I try docker image.
according to rabbitMQ, run command
1 | $ docker run -d --hostname my-rabbit --name some-rabbit -p 8080:15672 rabbitmq:3-management |
Apache CouchDB lets you access your data where you need it. The Couch Replication Protocol is implemented in a variety of projects and products that span every imaginable computing environment from globally distributed server-clusters, over mobile phones to web browsers.
Since I am working in treehouses/cli vagrant in which CouchDB docker already installed, I need to run couchDB docker.
1 | docker run -d -p 5984:984 --name=vmnet8 treehouses/couchdb:2.3.1 |
then open localhost:5984 on my browser

It shows couchDB installed

visit localhost:5984/_utils, you can see the new database npms is created
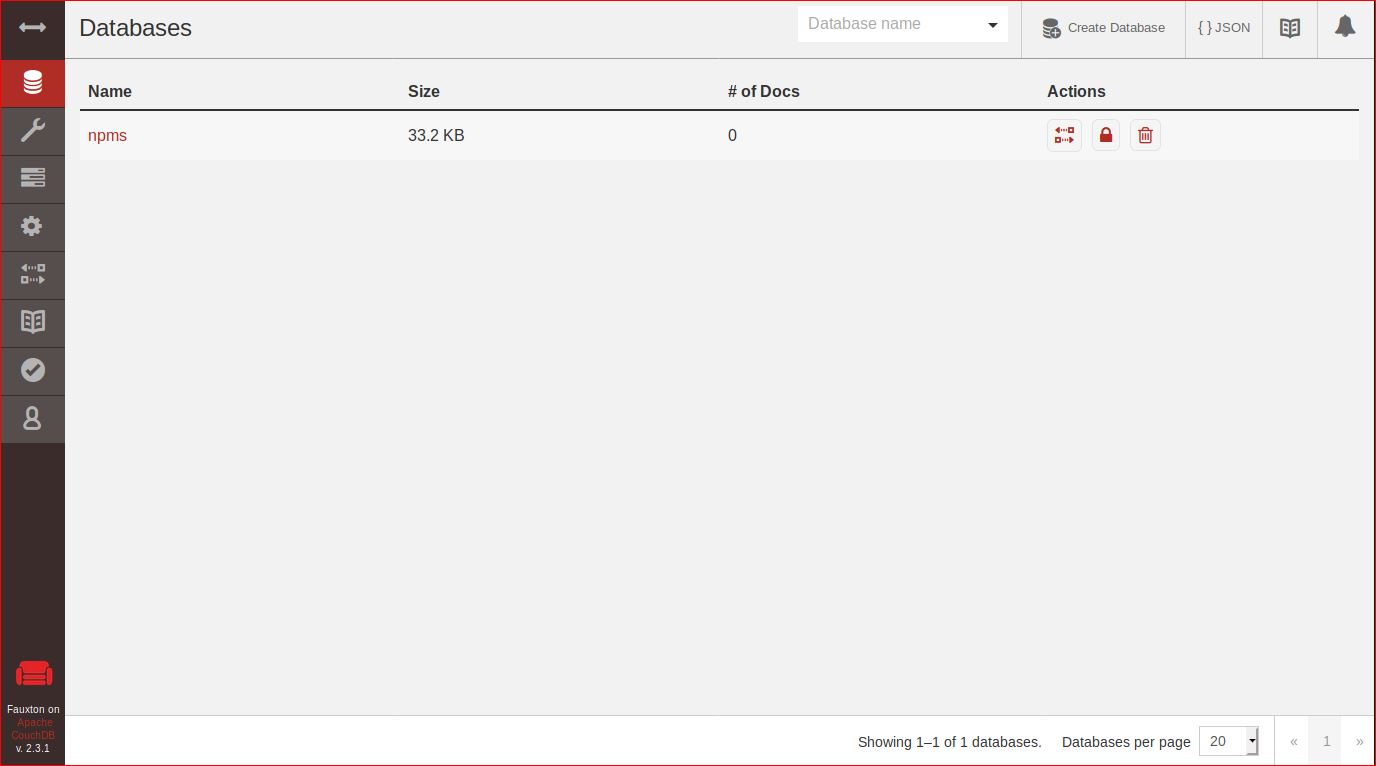
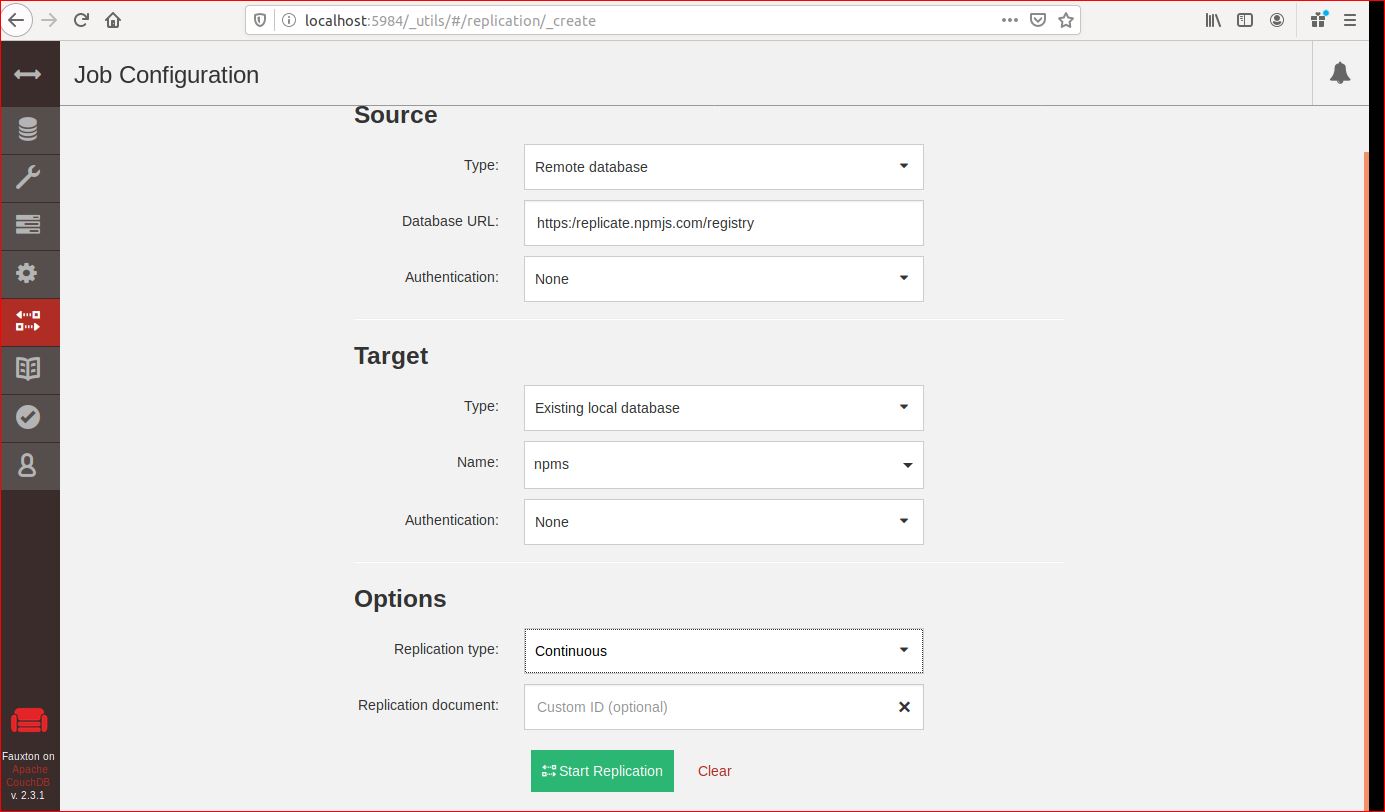
The npms-analyzer analyzes the npm ecosystem, collecting info, evaluating and scoring each package.In this project, I am going to create an experimental enviroment for treehouses cli package.
Configure Node.js Applications
1 | npm i config |
1 | vagrant@cli:~/npm_analyzer$ which node |
1 | vagrant@cli:~/npm_analyzer$ which git |
They are already in Ubuntu.
1 | vagrant@cli:~/npm_analyzer$ which tar |
1 | npm install -g pino-prteey |
to be contiuned
I need to simulate a npm repo to test codes. The following steps are how to create a npm repo.
Go to npmjs.com, click “join for free”, then create your account. The weird thing is the password needs at least 10 characters!
1 | mkdir npm_own |
Because I want to test the code on github.com/treehouses/cli and don’t want to mess up the current repo, I copy the url to my local
1 | wget https://github.com/treehouses/cli/blob/master/package.json |
I try to create a repo named “flyingsaucer8”.
Using vim to make my own package.json based on treehouses package.json
1 | { |
I keep my resume on github, and is going to update it with my working experience changing.Since resume is written in markdown format on github, I need a PDF format when applying job on line. How to convert markdown file to PDF file easily?
You need to check markdown is already installed or not. If not, you need use apt install markdown to install it.
1 | anna@ubuntu1804:~$ which markdown |
Go to directory where your markdown file lies, run
1 | anna@ubuntu1804:~/git_repo/resume$ markdown resume.md resume.html |
you will convert resume.md markdown file to resume.html
then you can go to webbrowser to see this html file, to make sure it works.
To convert PDF file, you need to use wkhtmltopdf tool
1 | apt install wkhtmltopdf |
go to the same directory where the resume.md and resume.html lie, run
1 | wkhtmltopdf -s letter -B 25mm -T 25mm -L 25mm -R 25mm resume.html resume.pdf |
then you can get the PDF format resume file.
1 | anna@ubuntu1804:~/git_repo/resume$ ll |
Last time we talked about adding a host to oVirt engine, it looks like following:
Setting up storage is a prerequisite for a new data center because a data center cannot be initialized unless storage domains are attached and activated.
A storage domain is a collection of images that have a common storage domain contains complete images of templates and virtual machots), ISO files, and metadata about themselves. A storage domain can be made of either block devices (SAN - iSCSI or FCP) or a file system (NAS - NFS, GlusterFS, or other POSIX compliant file systems).
First I use another centOS as a nfs server,then attached it to storage domain.
1 | [root@cube4200 ~]# showmount -e |
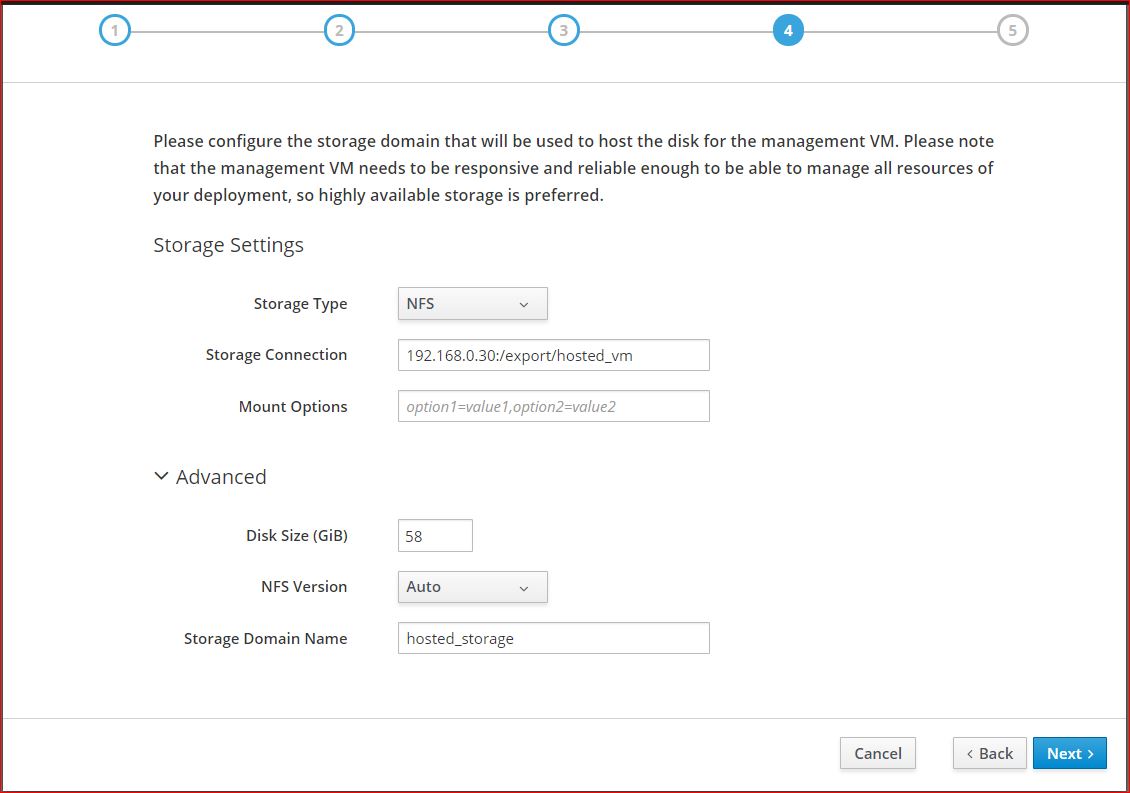
It is attached successfully.